| |
|
 |
ESTUDIO COLECTIVO DE DESPROTECCIONES
Última Actualizacion: 25/10/2001
|
|
|
|
|
Programa
|
Unpacker del PeCompact 1.41 |
W95 / W98 / NT
|
|
Descripción
|
Se trata del código que inyecta el compresor en los programas empaquetados con el, para que se puedan descomprimir
en memoria. |
|
Tipo
|
Packer |
|
Tipo de Tutorial
|
[X]Original, []Adaptación, []Aplicación, []Traducción |
|
Url
|
http://www.collakesoft.com |
|
Protección
|
Encriptación/Compresión |
|
Dificultad
|
1) Principiante, 2) Amateur, 3) Aficionado, 4) Profesional, 5) Especialista |
|
Herramientas
|
OllyDbg 1.03, WinHex, PeBuild |
|
Objetivo
|
Desentrañar cómo se descomprimen los programas comprimidos con PeCompact. |
|
Cracker
|
Mr. Khaki |
|
Grupo
|
www.whiskeykontekila.org |
|
Fecha
|
20 de Septiembre de 2001 |
| INTRODUCCION |
La historia empezó a la hora de querer proteger un poco más mi primer crackme, aquel famoso que servía
para obtener registro en el canal #crackers del Irc-Hispano. Si hubo por lo que me decidí a hacerlo con
el PeCompact fue porque lo dejaba realmente compacto, y eso me gustó. A medida que la gente fue estudiando
el crackme, y al ver sus respuestas cada vez me llamó más la atención. Alguno llegó
a pensar que el crackme estaba comprimido en varias capas (¿?). Otros tenían auténticos problemas
a la hora de desempaquetarlo, pues un script que había por ahí para el ProcDump no funcionaba.
A medida que la gente me iba diciendo todo esto, yo realmente descubría que mi crackme, atacarlo, no era
tan difícil, es más, mi mayor empeño estaba dirigido al algoritmo del serial, que eso fue
lo que trajo después de cabeza a muchos... mucho más que el antidebugging (por llamarlo de algún
modo), o que el packer.
A la hora de estudiar cómo funciona el PeCompact (especialmente el unpacker que va inyectado en los exe's
comprimidos) lo hice del siguiente modo. Cogí mi crackme, y lo comprimí con el PeCompact aplicándole
diversas opciones: el algoritmo de compresión, la razón de compresión (ratio), algoritmo fast
o small, etc... y después empecé a estudiarles 1 a 1. |
| AL ATAQUE |
|
Lo primero que hice nada más comprimir mi crackme, fue
echar una ojeada a las cabeceras (sí, cabeceras, porque no podéis olvidar que los PE también
llevan cabecera MZ).
Lo primero que vi al ojear la cabecera del crackme comprimido
con el PeCompact fue una especie de signatura (firma), que deja al inicio del fichero, concretamente en el offset
0CAh. La signatura consiste en un word (supuestamente un checksum?), y los caracteres PECO (figura 1). Y lo primero
que intenté, fue cambiar esa signatura, y ver que el fichero comprimido seguía funcionando.... y
así fue. Por tanto es una signatura que el compresor pone ahí, pero la podemos cambiar..... es decir,
una signatura que no nos va a servir para identificar los archivos que están comprimidos con PeCompact.

Fig. 1. La signatura del compresor en la cabecera
Otra de las cosas que pronto se ven al analizar
las cabeceras, es que las secciones de la cabecera PE la va nombrando como .pecn y .rsrc. Esto tampoco
nos debería servir para identificar el compresor, pues si renombramos las secciones del PE, el unpacker
no lo va a detectar, y eso provocará un despiste mayúsculo.
Así, pues, si queremos
buscar una signatura real par el PeCompact, lo que tenemos que hacer es ojear el código ejecutable en la
zona del Entry Point, es decir, el código que supuestamente tiene que descomprimir el exe comprimido. Esto
es un problema, pues por la cantidad de opciones que tiene el PeCompact pronto supuse que tendría varios
unpackers internos, así que fui mirando todas las posibilidades. Realmente la única diferencia está
en si se usa el algoritmo aPLiB o si se usa el JCALG1. Yo todo el estudio lo he hecho sobre el algoritmo aPLiB,
aunque seguramente el aspecto del unpacker para el JCALG1 es igual, salvo la rutina propia que descomprime los
datos.
Al mirar los ficheros en
la zona donde sitúa el Entry Point, observé que los primeros 178 bytes son prácticamente iguales,
salvo alguna ligera modificación. Y es partir de esa zona donde la rutina del JCALG1 se diferencia. Podríamos
por tanto coger cualquier cadena un poco larga como signatura... especialmente que en su representación
ASCII sea fácil de localizar. Hay una parte que es tremendamente diferenciadora: SSSSX-p (figura 2).

Fig. 2. Los 178 bytes primeros de la zona de Entry Point los podemos considerar como la
verdadera signatura del unpacker del PeCompact.
Bien, pues vista esta parte
interesante del unpacker, vamos a empezar a estudiar su código, y el modo en que va reconstruyendo el fichero
original.
|
| TRAZANDO CÓDIGO |
|
Normalmente los unpackers trabajan del modo siguiente:
desencriptan un pequeño bloque que es realmente el verdadero corazón del unpacker, desde ese kernel
del unpacker desempacan todo el código original del exe, alineándolo en memoria, desempacan la tabla
de importaciones, y construyen la IAT (Import Address Table / Tabla de Direcciones de Importación),este
trabajo normalmente lo hace el loader de Windows al cargar el exe en memoria, finalmente obtiene el Entry Point
original del programa (OEP), y salta a ese lugar para ejecutar el fichero reconstruido en memoria.
00404600 >EB 06 jmp short FAST_APL.00404608
00404602 68 00100000 push 1000
00404607 C3 retn
Estas son las 3 primeras líneas de código del
unpacker de PeCompact. Sencillo, ¿verdad?. Un jmp incondicional, un push
y un ret. Si nos olvidamos del jmp,
ya sabemos lo que haría esto... al meter 1000 en la pila, y provocar un ret,
el ultimo dato de la pila (1000) se tomaría como dirección de retorno... y sería como poner
un jmp 1000. Como dato ya preeliminar, decir que el número que
acompaña al push es el RVA del OEP. Si a ese numero le sumamos
la ImageBase, ya tendríamos el OEP (vaya con el PeCompact!!)
00404608 9C pushfd
00404609 60 pushad
0040460A E8 02000000 call FAST_APL.00404611
0040460F 33C0 xor eax,eax
00404611 8BC4 mov eax,esp
00404613 83C0 04 add eax,4
00404616 93 xchg eax,ebx
00404617 8BE3 mov esp,ebx
00404619 8B5B FC mov ebx,dword ptr ds:[ebx-4]
0040461C 81EB 0FA04000 sub ebx,40A00F
00404622 87DD xchg ebp,ebx
00404624 8B85 A6A04000 mov eax,dword ptr ss:[ebp+40A0A6]
0040462A 0185 03A04000 add dword ptr ss:[ebp+40A003],eax
00404630 66:C785 00A04000 >mov word ptr ss:[ebp+40A000],9090
00404639 0185 9EA04000 add dword ptr ss:[ebp+40A09E],eax
0040463F BB C3110000 mov ebx,11C3
00404644 039D AAA04000 add ebx,dword ptr ss:[ebp+40A0AA]
0040464A 039D A6A04000 add ebx,dword ptr ss:[ebp+40A0A6]
00404650 53 push ebx
00404651 53 push ebx
00404652 53 push ebx
00404653 53 push ebx
00404654 58 pop eax
00404655 2D 70A04000 sub eax,40A070
0040465A 8985 71A04000 mov dword ptr ss:[ebp+40A071],eax
00404660 5F pop edi
00404661 8DB5 70A04000 lea esi,dword ptr ss:[ebp+40A070]
00404667 B9 55040000 mov ecx,455
0040466C F3:A5 rep movs dword ptr es:[edi],dword ptr ds:[esi]
0040466E 5F pop edi
0040466F C3 retn
Bien, analicemos ahora todo
este bloque de código hasta el retn.
Con las 2 primeras instrucciones guarda los valores de los registros en la pila, y con el call siguiente lo que hace es, meter en la pila el valor 40460F
(dirección de retorno), y saltar a 404611. Desde 404611 hasta 404619 no hace más que recuperar el
dato que hay en la pila poniéndolo en el registro EBX, y resituar el valor de ESP.
Aquí viene un tema un poco complejo... fijaos que el unpacker se va a cargar en diferentes zonas de memoria,
dependiendo de la longitud que ocupe el programa previamente empaquetado. Ello obliga a que todos los offsets sean
relativos (código relocalizable), pero casi todas las instrucciones de tipo mov usan direcciones absolutas, por eso los unpackers lo que hacen es utilizar un registro (normalmente ebp), como índice para acceder a los datos
que estarían en falsas posiciones relativas.
Fijaos que a ese calor de
retorno que ha sacado de la pila (40460F) después le resta 40A00F, de este modo obtiene en EBP un valor negativo, que después lo usa como
índice para acceder a las variables que están en direcciones absolutas.
Por ejemplo: mov eax,dword ptr ss:[ebp+40A0A6] , al utilizar un
EBP negativo, está accediendo
realmente a la dirección 4046A6.
En el unpacker inicialmente
hay 3 pequeñas rutinas que no están ni encriptadas ni comprimidas: la inicial que estamos analizando
ahora, la que desempaca el kernel del unpacker, y la que contiene el algoritmo de descompresión.
Junto a estas 3 pequeñas rutinas se sitúan 5 datos necesarios: la dirección real donde se
encuentra la rutina de descompresión (la suele situar al final de la sección de la tabla de importación),
la ImageBase del fichero original, la ImageSize del fichero original, y la RVA de la sección que contiene
el unpacker.
Concretamente en 4046A6 lo
que está cogiendo es la ImageBase.
00404624 8B85 A6A04000 mov eax,dword ptr ss:[ebp+40A0A6]
0040462A 0185 03A04000 add dword ptr ss:[ebp+40A003],eax
00404630 66:C785 00A04000 >mov word ptr ss:[ebp+40A000],9090
00404639 0185 9EA04000 add dword ptr ss:[ebp+40A09E],eax
Estas
líneas son muy curiosas, pues parchean el Entry Point del unpacker. Con 9090 está nopeando
el primer jmp,
y con los add
lo que hace es sumar la ImageBase al RVA del OEP que está en el push. Con esto lo que ocurre es que la entrada del unpacker se queda parcheada
de este modo:
00404600 >90 nop
00404601 90 nop
00404602 68 00104000 push 401000
00404607 C3 retn
Si
en este momento nosotros hacemos un dump de la memoria a un fichero, el unpacker ya no funcionará, pues
estamos provocando que salte al OEP (esto es una gran ventaja, pues a la hora de desempaquetar a mano nos va a
evitar tener que modificar el Entry Point por el OEP.
0040463F BB C3110000 mov ebx,11C3
00404644 039D AAA04000 add ebx,dword ptr ss:[ebp+40A0AA]
0040464A 039D A6A04000 add ebx,dword ptr ss:[ebp+40A0A6]
00404650 53 push ebx
00404651 53 push ebx
00404652 53 push ebx
00404653 53 push ebx
00404654 58 pop eax
00404655 2D 70A04000 sub eax,40A070
0040465A 8985 71A04000 mov dword ptr ss:[ebp+40A071],eax
En
esta zona se vuelve a calcular un nuevo EBP relativo, para poder trabajar más adelante con offsets y tomar valores de
las variables. En EBX
va sumando 11C3, le suma la ImageSize del fichero original, y también la ImageBase. Con estas sumas calcula
una dirección en una zona de memoria donde va a realojar código ejecutable. Con el mov dword ptr ss:[ebp+40A071],eax,
está modificando código en tiempo de ejecución que ahora veremos.
00404660 5F pop edi
00404661 8DB5 70A04000 lea esi,dword ptr ss:[ebp+40A070]
00404667 B9 55040000 mov ecx,455
0040466C F3:A5 rep movs dword ptr es:[edi],dword ptr ds:[esi]
0040466E 5F pop edi
0040466F C3 retn
Finalmente,
realoja parte del código en una zona de memoria que está libre. (parte del código que ha realojado
corresponde al kernel del unpacker. Finalmente, con el retn salta al código que acaba de realojar... (usa muchos datos tomados
de la pila, que los guardó con todos los push ebx).
Ahora
analizaremos el trozo de código que ha realojado, y que también ha modificado en tiempo de ejecución.
00404670 BD 0000000 mov ebp, 0
00404675 57 push edi
00404676 5E pop esi
00404677 83C6 42 add esi,42
0040467A 81C7 53110000 add edi,1153
00404680 56 push esi
00404681 57 push edi
00404682 57 push edi
00404683 56 push esi
00404684 FF95 9EA04000 call dword ptr ss:[ebp+40A09E]
0040468A 8BC8 mov ecx,eax
0040468C 5E pop esi
0040468D 5F pop edi
0040468E 8BC1 mov eax,ecx
00404690 C1F9 02 sar ecx,2
00404693 F3:A5 rep movs dword ptr es:[edi],dword ptr ds:[esi]
00404695 03C8 add ecx,eax
00404697 83E1 03 and ecx,3
0040469A F3:A4 rep movs byte ptr es:[edi],byte ptr ds:[esi]
0040469C EB 14 jmp short FAST_APL.004046B2
Se
trata de un bloque muy pequeño, pero muy importante. Es precisamente el que se encarga de desempaquetar
el kernel del unpacker, y pasarle a él el control. Este bloque se encuentra duplicado, pues se ha
realojado en otra zona de memoria (después veremos gráficamente qué galimatías ha hecho
el unpacker). El mov ebp,0
se ha modificado previamente en tiempo de ejecución, justo antes de realojarlo en otra zona de memoria,
de este modo el 0 lo cambia por un numero calcula que nuevamente lo usa como índice para referirse a offsets
de variables. A la entrada de esta rutina, edi contiene la dirección donde ha sido realojada, por lo que se pasa
a esi (push edi, pop esi),
y se le suma 42 (longitud en bytes de este bloque de código, más 5 dwords que son variables que ya
se han usado anteriormente). A edi
le suma 1153, colocándolo en una zona de memoria libre y amplia. El call, es una llamada a la rutina que contiene el algoritmo de descompresión,
y como parámetros solo hay que pasarla en esi la dirección del código comprimido, y en edi la dirección del buffer
donde va a colocar el código descomprimido. El algoritmo de descompresión devuelve en eax la longitud de bytes
descomprimidos.
Lo
que hace después del call
es tapar el código comprimido del kernel del unpacker con el código que hay descomprimido
ya en el buffer. Y a continuación, mediante el jmp, salta al kernel de unpacker, que ya está descomprimido y
realojado (figura 3).
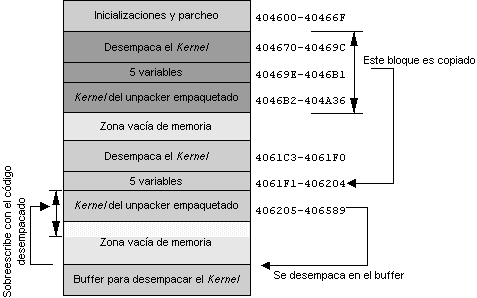
Fig. 3. Gráfica con todos los bloques de código y
buffers que mueve.
Según
la gráfica anterior, podríamos hacer un breve resumen: En Inicializaciones y parcheo, el código
simplemente parchea el Entry Point, poniendo en él un salto al Original Entry Point, y copia la memoria
que hay en 404670-404A36 en 4061C3, saltando después a ejecutar el bloque de Desempaca el Kernel. El bloque
Desempaca el Kernel sencillamente desempaca el Kernel del unpacker empaquetado en Buffer para desempacar el
Kernel, y acto seguido sobrescribe Kernel de unpacker empaquetado con lo que ha desempacado en Buffer para
desempacar el Kernel. Finalmente se haría un salto a la zona Kernel del unpacker empaquetado, que ahora
tiene el kernel de unpacker desempacado.
Veamos pues
el contenido del kernel del unpacker, es decir,
el corazón real del unpacker.
|
| ESTO SE PONE SERIO |
|
Bien,
si hemos entendido hasta aquí todo lo que hemos ido trazando, veremos que aún falta lo más
complicado del unpacker. Pensemos un poco cómo es un fichero PE, cómo se estructura el fichero cargado
en memoria, y qué significa la palabra empaquetar (pack). Debido a la propia estructura PE, y debido al
alineamiento que existe dentro del fichero, hay muchos bytes que se pierden, es decir, espacio en el fichero que
realmente no es útil y suele estar rellenada con 0.
El packer, por tanto, debe quitar todo ese espacio, para que realmente esa información
inútil no ocupe espacio en el fichero final comprimido. Por tanto el unpacker debería reorganizar
toda esa información inútil que aunque no esté comprimida en el fichero final, sí que
debe mantenerla.
Aquí ha salido una palabra que va a ser clave para entender cómo funciona
el loader y el unpacker, a saber: alineamiento. Si estamos acostumbrados a trabajar con ficheros PE, sabremos que
estos están formados por secciones.
Cada sección es un bloque de datos, que tienen una cabecera especificando
las características de cada sección. Dentro de esas características hay: Physical RVA, Physical
Size, Virtual RVA, y Virtual Size. Los datos physical hacen referencia a los offset del fichero. Así pues,
si una sección tiene Physical RVA igual a 400h, significa que los datos de esa sección empiezan en
el offset 400h del fichero.
Los datos Virtual hacen referencia a dónde se organizará esa sección
en el mapeado de memoria (empezando siempre desde la ImageBase). Así, si la sección anterior tiene
Virtual RVA igual a 3000h, significa que esa sección se cargaría en la zona de memoria ImageBase+3000h
(figura 4). Y aquí viene el meollo del alineamiento... Si el fichero tiene un alineamiento de 200h, significa
que las secciones tienen que tener un tamaño que sea múltiplo de 200h. Así si una sección
tiene un Physical RVA de 500h y un Physical Size de 35h, realmente ocuparía 200h, ya que por el alineamiento
la siguiente sección debería empezar en 500h+200h. Si su Physical Size fuera de 235h, ocuparía
400h (el número más próximo múltiplo de 200h). El espacio montante que se añade
para alinear el fichero normalmente se rellena con 0.
Y ahora viene el problema real.... normalmente el alineamiento del fichero suele
ser muy pequeño. Pero no ocurre lo mismo con el alineamiento de memoria (Object Alignment), que normalmente
suele ser de 1000h. Normalmente los compiladores y el linker suelen asignar bloques consecutivos para posicionar
cada sección, aunque siempre respetando el alineamiento.

Fig. 4. Esquema de carga de una sección del fichero a la
memoria.
Bueno,
pues visto esto... veamos ahora el kernel del unpacker.
00406205 8BB5 A6A04000 mov esi,dword ptr ss:[ebp+40A0A6]
0040620B 56 push esi
0040620C 03B5 AEA04000 add esi,dword ptr ss:[ebp+40A0AE]
00406212 57 push edi
00406213 83C6 14 add esi,14
00406216 03B5 11A64000 add esi,dword ptr ss:[ebp+40A611]
0040621C 8DBD 15A64000 lea edi,dword ptr ss:[ebp+40A615]
00406222 B9 06000000 mov ecx,6
00406227 F3:A5 rep movs dword ptr es:[edi],dword ptr ds:[esi]
00406229 5F pop edi
0040622A 6A 04 push 4
0040622C 68 00100000 push 1000
00406231 FFB5 2DA64000 push dword ptr ss:[ebp+40A62D]
00406237 6A 00 push 0
00406239 FF95 1DA64000 call dword ptr ss:[ebp+40A61D]
0040623F 8BF8 mov edi,eax
00406241 5B pop ebx
00406242 019D 38A34000 add dword ptr ss:[ebp+40A338],ebx
00406248 8DB5 43A64000 lea esi,dword ptr ss:[ebp+40A643]
0040624E 60 pushad
0040624F 8D85 C3AD4000 lea eax,dword ptr ss:[ebp+40ADC3]
00406255 8B95 A6A04000 mov edx,dword ptr ss:[ebp+40A0A6]
0040625B FFD0 call eax
0040625D 61 popad
0040625E 57 push edi
0040625F AD lods dword ptr ds:[esi]
00406260 0BC0 or eax,eax
00406262 74 6C je short FAST_APL.004062D0
00406264 8BD0 mov edx,eax
00406266 0395 A6A04000 add edx,dword ptr ss:[ebp+40A0A6]
0040626C AD lods dword ptr ds:[esi]
0040626D 56 push esi
0040626E 8BC8 mov ecx,eax
00406270 57 push edi
00406271 52 push edx
00406272 8BF2 mov esi,edx
00406274 8B85 15A64000 mov eax,dword ptr ss:[ebp+40A615]
0040627A 8B9D 19A64000 mov ebx,dword ptr ss:[ebp+40A619]
00406280 E8 910A0000 call FAST_APL.00406D16
00406285 5A pop edx
00406286 5F pop edi
00406287 52 push edx
00406288 57 push edi
00406289 FF95 9EA04000 call dword ptr ss:[ebp+40A09E]
0040628F 0BC0 or eax,eax
00406291 74 07 je short FAST_APL.0040629A
00406293 8BC8 mov ecx,eax
00406295 5E pop esi
00406296 5F pop edi
00406297 EB C5 jmp short FAST_APL.0040625E
El bloque anterior la que hace es
ir descomprimiendo cada sección con nombre .pecn. El modo en que accede a ellas es mediante una
tabla interna, por lo que no es necesario que las secciones conserven ese nombre.
Veamos cómo lo hace:
Desde 406205 hasta 406229 lo que hace es copiar las direcciones reales
de las funciones de la tabla de importación a una tabla propia y por tanto más accesible por el unpacker,
y que posteriormente van ser utilizadas. De este modo tienes una tabla de direcciones de las APIs y no tiene
que estar buscándolas en la IAT del fichero comprimido. Las direcciones que carga de la IAT son las de las
siguientes funciones (en el mismo orden que él las carga): LoadLibraryA, GetProcAddress, VirtualAlloc, VirtualFree,
ExitProcess, GetModuleHandleA.
Un problema de las rutinas que tienen
que descomprimir código es que se necesita un buffer donde descomprimir, por lo que necesita crear un buffer.
Para crearlo llama a la API VirtualAlloc, haciéndolo del modo siguiente: desde 40622A hasta 406237 mete
los argumentos en la pila (en orden inverso ;o), para posteriormente hacer un call
al address directo de la API (que se encuentra en la tabla que acaba de crear antes). Los argumentos pasados son:
0, una variable que se encontraba comprimida con el kernel, 1000h, y 4. Veamos cuáles son los argumentos
de esa API:
LPVOID VirtualAlloc(
LPVOID lpAddress, // address of region to reserve or commit
DWORD dwSize, // size of region
DWORD flAllocationType, // type of allocation
DWORD flProtect // type of access protection
);
lpAddress si tiene valor
NULL (0), deja que el propio sistema busque una zona de memoria, y lo asigne, devolviéndonos en eax
la dirección de inicio del bloque alojado. Como dwSize se le ha pasado la variable que estaba comprimida
con el unpacker, por lo que presumiblemente debe ser el tamaño máximo que tiene que descomprimir.
Como flAllocationType se le ha pasado un valor fijo, 1000h, que si miramos en las definiciones de windows.inc
corresponde a MEM_COMMIT, y como flProtect se le ha pasado 4, que mirando en windows.inc corresponde a PAGE_READWRITE.
Por tanto aquí se asigna un bloque de memoria para lectura y escritura de un tamaño en bytes suficientemente
grande como para servir de buffer a cada sección (luego veremos que esto no es del todo cierto, porque el
buffer se usa de almacenamiento temporal y no como buffer para descomprimir en él).
A partir de este momento lo que
hace es ir descomprimiendo cada sección sobre sí misma. De este modo deja todo el trabajo sucio al
propio sistema. Es decir, a cada sección le asigna en el fichero comprimido un VirtualSize suficiente como
para poder alojar ahí el código comprimido. De este modo es el loader de Windows quien asigna la
memoria. El modo en que va a descomprimir las secciones es el siguiente: primero copia la sección comprimida
en el buffer y después descomprime el buffer sobre la propia sección (figura 5).

Fig. 5. Los 2 pasos que hace con cada sección para descomprimirla.
Analicemos esto sobre el código:
Después del call
que llama a VirtualAlloc hace una de las operaciones más importantes en el unpcker... parchea las
últimas instrucciones del unpacker, sumando al RVA del OEP la ImageBase. Justamente con este comando add dword ptr ss:[ebp+40A338],ebx cambia el
push que contiene el RVA del OEP. Justo después de este push ejecuta un retn, es decir,
que en el push está realmente el OriginalEntryPoint.
El PeCompact permite comprimir los
archivos incluyendo diversos plugins. Existen varios tipos de plugins... encrypt, decrypt, pre-operative, post-operative,
GPA (GetProcAddress Hook), y ExtraData. Justo después de haber alojado el buffer en memoria, haber situado
el OEP, y antes de empezar a desempaquetar las secciones debería ejecutar el plugin pre-operative. Esto
lo hace desde 406248 hasta 40625D. Fijémonos que antes del call eax
guarda todos los registros en la pila, para recuperarlos después del call.
Si no existe ningún plugin, eax apuntará a una parte del
unpacker que está rellenada con 0C3h (retn), de tal modo que
estas lineas no hacen nada.
A partir de ese momento la rutina
sitúa esi apuntando a una tabla que tiene todas las RVA de las
secciones que tienen datos comprimidos, y la longitud (en bytes) de cada sección (longitud real, no alineada).
Y mediante un bucle que se van leyendo los datos de esa tabla, hasta que encuentre una RVA que sea 0. Un dato importante
de la rutina que tiene el algoritmo de descompresión es que si hay un error del código empaquetado
en eax devuelve 0, mientras que si no hay errores devuelve la longitud
en bytes de lo que ha descomprimido.
Veamos este bucle parte a parte:
0040625F AD lods dword ptr ds:[esi]
00406260 0BC0 or eax,eax
00406262 74 6C je short FAST_APL.004062D0
Este es el inicio del bucle. Lee
un dato de la tabla que tiene las RVA de las secciones empaquetadas (la llamaremos por ejemplopecRVA_list).
Si el dato leído es 0, terminaría el bucle, saltando a 4062D0, si el RVA leído no es 0, entra
en el bucle. La tabla pecRVA_list es una tabla de dwords que tendría 2 dword por cada sección comprimida,
en el primero estaría la RVA de la sección, y en el segundo dword estaría la longitud en bytes
de código comprimido en la sección.
00406264 8BD0 mov edx,eax
00406266 0395 A6A04000 add edx,dword ptr ss:[ebp+40A0A6]
0040626C AD lods dword ptr ds:[esi]
0040626D 56 push esi
0040626E 8BC8 mov ecx,eax
00406270 57 push edi
00406271 52 push edx
En este momento mete en edx el RVA
que ha leído de la tablapecRVA_list, para sumarle la ImageBase (add
edx,dword ptr ss:[ebp+40A0A6]), a continuación carga en eax el
siguiente dword de la pecRVA_list, que correspondería a la longitud en bytes de datos empaquetados
en esa sección, pasándolo a eax. Finalmente guarda esi (apunta al siguiente dato en pecRVA_list) y edx
(dirección de la sección) en la pila.
A continuación carga en eax y en ebx 2 valores de la tabla
que creó anteriormente desde la IAT. Concretamente carga en eax la
dirección de LoadLibraryA y en ebx la dirección de GetProcAddress,
llamando posteriormente a 406D16. Hemos de tener en cuenta que justamente después de este call
está el call a la rutina que tiene el algoritmo de descompresión. Si nos fijamos, hemos dicho
que uno de los plugins es de tipo Encrypt... pues aquí nos encontramos justamente con el plugin Decrypt
(:o). En la dirección 406D16 de hecho no hay más que una pequeña rutina que simplemente copia
los datos de la sección empaquetada al buffer que hemos creado con VirtualAlloc. Una rutina, eso sí,
seguida por un motón de 0C3h (retn).
00406D16 8BC1 mov eax,ecx
00406D18 C1F9 02 sar ecx,2
00406D1B F3:A5 rep movs dword ptr es:[edi],dword ptr ds:[esi]
00406D1D 03C8 add ecx,eax
00406D1F 83E1 03 and ecx,3
00406D22 F3:A4 rep movs byte ptr es:[edi],byte ptr ds:[esi]
00406D24 C3 retn
Finalmente,
después de llamar a la rutina 406d16 que desencripta con el plugin (si existe), y copia la sección
en el buffer, se llama a la rutina que tiene el algoritmo de descompresión. Esta rutina, recordemos, devuelve
eax a 0
si hay algún error, y si no hay error devuelve en eax
la longitud en bytes de lo que se ha descomprimido. Si por
alguna extraña circunstancia se produce un error al descomprimir los datos de las secciones, se llama
a una rutina que apenas comentaré, pues con los comentarios que añade el propio OllyDbg creo que
queda muy claro qué es lo que hace.
0040629A 8D9D 97A54000 lea ebx,dword ptr ss:[ebp+40A597] ; EBX='USER32.DLL'
004062A0 53 push ebx
004062A1 FF95 15A64000 call dword ptr ss:[ebp+40A615] ; LoadLibraryA
004062A7 8D9D A2A54000 lea ebx,dword ptr ss:[ebp+40A5A2] ; MessageBoxA
004062AD 53 push ebx
004062AE 50 push eax
004062AF FF95 19A64000 call dword ptr ss:[ebp+40A619] ; GetProcAddress
004062B5 8D9D B8A54000 lea ebx,dword ptr ss:[ebp+40A5B8] ; 'This executable is corrupt![...]'
004062BB 8D8D EEA54000 lea ecx,dword ptr ss:[ebp+40A5EE] ; 'Authentification Check Failure'
004062C1 6A 10 push 10
004062C3 51 push ecx
004062C4 53 push ebx
004062C5 6A 00 push 0
004062C7 FFD0 call eax ; MessageBoxA
004062C9 FFA5 25A64000 jmp dword ptr ss:[ebp+40A625] ; ExitProcess
Y
una vez acabado el bucle, saltaría a 40625E, donde se lee una nueva RVA de pecRVA_list, y si no es 0 volvería
a ejecutar el bucle. Cuando encuentra una RVA que es 0, interpreta que es el final de la lista, y continua en 4062D0.
En la dirección 4062D0 nos encontramos una rutina muy similar a la que acabamos
de ver. Una de las opciones al empaquetar un fichero con el PeCompact es unir varias secciones en una sola. De
este modo podemos reducir el tamaño de alineamiento del fichero original, y lo que hace el unpacker en esta
rutina que vamos a analizar ahora es exactamente eso, reordenar las secciones que han sido empaquetadas juntas
en cada sección.
En 4062D0 encontramos el siguiente bloque de código:
004062D0 58 pop eax
004062D1 8DB5 C3A64000 lea esi,dword ptr ss:[ebp+40A6C3]
004062D7 AD lods dword ptr ds:[esi]
004062D8 0BC0 or eax,eax
004062DA 74 74 je short FAST_APL.00406350
004062DC 0385 A6A04000 add eax,dword ptr ss:[ebp+40A0A6]
004062E2 8BD8 mov ebx,eax
004062E4 AD lods dword ptr ds:[esi]
004062E5 0385 A6A04000 add eax,dword ptr ss:[ebp+40A0A6]
004062EB 8BD0 mov edx,eax
004062ED AD lods dword ptr ds:[esi]
004062EE 8BC8 mov ecx,eax
004062F0 57 push edi
004062F1 56 push esi
004062F2 8BF3 mov esi,ebx
004062F4 57 push edi
004062F5 51 push ecx
004062F6 8BC1 mov eax,ecx
004062F8 C1F9 02 sar ecx,2
004062FB F3:A5 rep movs dword ptr es:[edi],dword ptr ds:[esi]
004062FD 03C8 add ecx,eax
004062FF 83E1 03 and ecx,3
00406302 F3:A4 rep movs byte ptr es:[edi],byte ptr ds:[esi]
00406304 59 pop ecx
00406305 5E pop esi
00406306 8BFA mov edi,edx
00406308 8BC1 mov eax,ecx
0040630A C1F9 02 sar ecx,2
0040630D F3:A5 rep movs dword ptr es:[edi],dword ptr ds:[esi]
0040630F 03C8 add ecx,eax
00406311 83E1 03 and ecx,3
00406314 F3:A4 rep movs byte ptr es:[edi],byte ptr ds:[esi]
00406316 5E pop esi
00406317 AD lods dword ptr ds:[esi]
00406318 8BC8 mov ecx,eax
0040631A 8BD0 mov edx,eax
0040631C 33C0 xor eax,eax
0040631E C1F9 02 sar ecx,2
00406321 F3:AB rep stos dword ptr es:[edi]
00406323 03CA add ecx,edx
00406325 83E1 03 and ecx,3
00406328 F3:AA rep stos byte ptr es:[edi]
0040632A 8B7E F0 mov edi,dword ptr ds:[esi-10]
0040632D 03BD A6A04000 add edi,dword ptr ss:[ebp+40A0A6]
00406333 8B4E F4 mov ecx,dword ptr ds:[esi-C]
00406336 038D A6A04000 add ecx,dword ptr ss:[ebp+40A0A6]
0040633C 2BCF sub ecx,edi
0040633E 8BD1 mov edx,ecx
00406340 C1F9 02 sar ecx,2
00406343 F3:AB rep stos dword ptr es:[edi]
00406345 03CA add ecx,edx
00406347 83E1 03 and ecx,3
0040634A F3:AA rep stos byte ptr es:[edi]
0040634C 5F pop edi
0040634D EB 88 jmp short FAST_APL.004062D7
Prácticamente
todo el bloque es un bucle, concretamente desde 4062D7 hasta 40634D es el bucle que va reorganizando cada sección
que se ha descomprimido. El modo de hacerlo es sencillo. Al entrar en 4062D0 en la pila ha quedado como último
dato la dirección donde está el buffer que hemos alojado en memoria previamente. Y en 4062D1, con
posiciona esi sobre
una tabla de dwords que contiene los datos para reorganizar todas las secciones (a esta tabla la llamaremos mergedObjects_list).
En esta lista se encuentran 4 dwords por cada sección que se ha mezclado en cada sección. Explicaré
esto un poco más detalladamente.
Lo que hace el PeCompact es coger las secciones originales, y quitándolas
la alineación propia de fichero, colocarlas secuencialmente, empaquetarlas, y guardar esa información
en una sola sección. El problema es que para reorganizar eso de nuevo necesita saber, en qué posición
y qué longitud tiene cada sección una vez desempaquetada esa sección, y qué RVA (y
su alineamiento) le corresponde a cada sección de las que ha mezclado en esa sección. Todos esos
valores los guarda en la tabla mergedObjects_list.
En 4062D7, carga un dword de la tabla mergedObjects_list, y si es 0, sale
del bucle saltando a 406350. Si no es 0, a ese valor le suma la ImageBase., metiendo su valor en ebx. Lee un nuevo dword de la
tabla, al cual le suma la ImageBase también y mete ese valor en edx. Si a esos valores les suma la ImageBase podemos suponer ya que son RVA's
(Relative Virtual Addresses). En 4062ED carga de la mergedObjects_list un nuevo dword, cuyo valor lo guarda
en ecx.
En
la zona de 4062F0 a 406305 lo que hace es copiar memoria al buffer. Pero ¿qué es lo que copia? Bien
sencillo. Hemos dicho que el PeCompact mezclaba las secciones secuencialmente en una sola sección. Pues
bien, lo que hace es copiar en el buffer una de esas secciones que está mezcla en la sección ya desempaquetada.
Para ello ha tomado varios valores de megedObjects_list, concretamente ha tomado un RVA que indica dentro
de la sección ya desempaquetada dónde empieza la sección; el siguiente dato que ha leído
de mergedObjects_list ha sido el VirtualRVA real que le correspondía a esa sección, para realojarla
en memoria; y el siguiente dato que ha leído de mergedObject_list es la longitud en bytes que ocupa
la sección desempaquetada (tamaño que no se corresponde al PhysicalSize de la sección original,
pues aquí quita ceros finales, y otras cosas que son innecesarias).
En 406317 se lee otro dword de mergedObjects_list,
que es usado como longitud en bytes a rellenar con ceros (0h), después de realojar la sección en
su VirtualRVA original. Si nos fijamos todo este proceso se podría hacer sin usar el buffer como intermediario
en los movimientos de memoria, pero se hace para que no se solape en ningún momento la sección que
tiene todas las secciones mezcladas, con cada una de las secciones que se va colocando. Finalmente, desde 40632A
hasta 40634C lo que se hace es poner a 0 la sección mezclada. Para que en ningún momento haya solapamiento,
ni se sobrescriba ninguna sección el unpacker las va realojando empezando por la sección cuyo RVA
es más alto (está más abajo en la memoria). (figura 6).
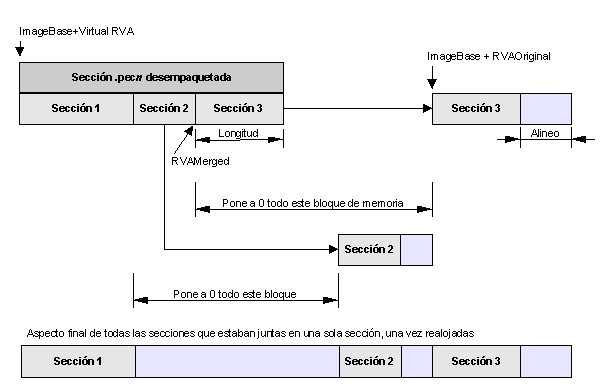
Fig. 6. En este diagrama se muestran los significados de cada valor tomado de la tabla mergedObjects_list.
En la lista se guardan en el siguiente orden: RVAMerged, RVAOriginal, Longitud, Alineo. Hay que tener en cuenta
que cada sección (sección1, sección2 y sección3) necesitarían tomar estos datos
de la tabla.
Según lo que acabamos de
ver daría la sensación que una vez realojadas todas las secciones en sus RVA originales podríamos
volcar el proceso que está en memoria ya directamente sobre un fichero, pues una de las secciones que se
han desempaquetado ha sido la que contiene la tabla de importaciones. Sin embargo esto no es del todo correcto,
pues una de las cosas que hace el PeCompact antes de empaquetar el código, es modificar los argumentos de
los opcodes que son de tipo call y
jmp. Por tanto, una vez desempaquetadas las secciones debe rastrear el código, para restablecer los
argumentos de esos opcodes. Eso es precisamente lo que hace a partir de 406350. Otra de las cosas que está
pendiente por hacer, es rellenar la IAT (ImportAddressTable), ya que esto normalmente lo hace el loader de Windows,
y en esta ocasión el loader sólo ha llenado la IAT del unpacker, pero no de la Tabla de Importaciones
que estaba empaquetada, y que era la original del fichero.
Analicemos, pues, lo que hace a
partir de 406350:
00406350 57 push edi
00406351 8BBD D7A44000 mov edi,dword ptr ss:[ebp+40A4D7]
00406357 03BD A6A04000 add edi,dword ptr ss:[ebp+40A0A6]
0040635D 8B8D DBA44000 mov ecx,dword ptr ss:[ebp+40A4DB]
00406363 33D2 xor edx,edx
00406365 33DB xor ebx,ebx
00406367 33F6 xor esi,esi
00406369 03FE add edi,esi
0040636B 03DE add ebx,esi
0040636D 49 dec ecx
0040636E 74 72 je short FAST_APL.004063E2
00406370 78 70 js short FAST_APL.004063E2
00406372 66:8B07 mov ax,word ptr ds:[edi]
00406375 2C E8 sub al,E8
00406377 3C 01 cmp al,1
00406379 76 38 jbe short FAST_APL.004063B3
0040637B 66:3D 1725 cmp ax,2517
0040637F 74 51 je short FAST_APL.004063D2
00406381 3C 27 cmp al,27
00406383 75 0A jnz short FAST_APL.0040638F
00406385 80FC 80 cmp ah,80
00406388 72 05 jb short FAST_APL.0040638F
0040638A 80FC 8F cmp ah,8F
0040638D 76 05 jbe short FAST_APL.00406394
0040638F 47 inc edi
00406390 43 inc ebx
00406391 EB DA jmp short FAST_APL.0040636D
00406393 B8 8B470290 mov eax,9002478B ;Código ofuscado
00406398 90 nop ; Realmente es :
00406399 90 nop ; db B8
0040639A 90 nop ; mov eax,dword ptr ds:[edi+2]
0040639B 90 nop ; Fijarse bien en la linea que lo invoca
0040639C 90 nop ; desde 40638D
0040639D 90 nop
0040639E 90 nop
0040639F 90 nop
004063A0 90 nop
004063A1 90 nop
004063A2 90 nop
004063A3 90 nop
004063A4 2BC3 sub eax,ebx
004063A6 8947 02 mov dword ptr ds:[edi+2],eax
004063A9 BE 06000000 mov esi,6
004063AE 83E9 05 sub ecx,5
004063B1 EB B6 jmp short FAST_APL.00406369
004063B3 8B47 01 mov eax,dword ptr ds:[edi+1]
004063B6 3C 01 cmp al,1
004063B8 75 D5 jnz short FAST_APL.0040638F
004063BA 66:C1E8 08 shr ax,8
004063BE C1C0 10 rol eax,10
004063C1 86C4 xchg ah,al
004063C3 2BC3 sub eax,ebx
004063C5 8947 01 mov dword ptr ds:[edi+1],eax
004063C8 BE 05000000 mov esi,5
004063CD 83E9 04 sub ecx,4
004063D0 EB 97 jmp short FAST_APL.00406369
004063D2 0157 02 add dword ptr ds:[edi+2],edx
004063D5 BE 06000000 mov esi,6
004063DA 83EA 04 sub edx,4
004063DD 2BCE sub ecx,esi
004063DF 41 inc ecx
004063E0 EB 87 jmp short FAST_APL.00406369
004063E2 5F pop edi
004063E3 E8 8D010000 call FAST_APL.00406575
004063E8 68 00400000 push 4000
004063ED 6A 00 push 0
004063EF 57 push edi
004063F0 FF95 21A64000 call dword ptr ss:[ebp+40A621]
004063F6 E8 97000000 call FAST_APL.00406492
004063FB 73 79 jnb short FAST_APL.00406476
004063FD 8D9D 97A54000 lea ebx,dword ptr ss:[ebp+40A597] ; USER32.DLL
00406403 53 push ebx
00406404 FF95 15A64000 call dword ptr ss:[ebp+40A615] ; LoadLibraryA
0040640A 8985 D7A44000 mov dword ptr ss:[ebp+40A4D7],eax
00406410 8D9D AEA54000 lea ebx,dword ptr ss:[ebp+40A5AE] ; wsprintfA
00406416 53 push ebx
00406417 50 push eax
00406418 FF95 19A64000 call dword ptr ss:[ebp+40A619] ; GetProcAddress
0040641E 8D9D C3A74000 lea ebx,dword ptr ss:[ebp+40A7C3]
00406424 53 push ebx
00406425 83BDE7A4400001 cmp dword ptr ss:[ebp+40A4E7],1 ; Es nombre u ordinal?
0040642C 74 08 je short FAST_APL.00406436
0040642E 8D8D 45A54000 lea ecx,dword ptr ss:[ebp+40A545] ; 'Procedure couldn't be found'
00406434 EB 06 jmp short FAST_APL.0040643C
00406436 8D8D 01A54000 lea ecx,dword ptr ss:[ebp+40A501] ; 'Ordinal couldn't be located'
0040643C 8B95 DFA44000 mov edx,dword ptr ss:[ebp+40A4DF] ; Funcion del error
00406442 8BBD E3A44000 mov edi,dword ptr ss:[ebp+40A4E3] ; Modulo del error
00406448 57 push edi
00406449 52 push edx
0040644A 51 push ecx
0040644B 53 push ebx
0040644C FFD0 call eax ; wsprintfA
0040644E 8D9D A2A54000 lea ebx,dword ptr ss:[ebp+40A5A2] ; MessageBoxA
00406454 53 push ebx
00406455 FFB5 D7A44000 push dword ptr ss:[ebp+40A4D7]
0040645B FF95 19A64000 call dword ptr ss:[ebp+40A619] ; GetProcAddess
00406461 5B pop ebx
00406462 8D8D EBA44000 lea ecx,dword ptr ss:[ebp+40A4EB] ; 'Entry point not found'
00406468 6A 10 push 10
0040646A 51 push ecx
0040646B 53 push ebx
0040646C 6A 00 push 0
0040646E FFD0 call eax ; MessageBoxA
00406470 FFA5 25A64000 jmp dword ptr ss:[ebp+40A625] ; ExitProcess
00406476 8BB5 15A64000 mov esi,dword ptr ss:[ebp+40A615]
0040647C 8BBD 19A64000 mov edi,dword ptr ss:[ebp+40A619]
00406482 E8 8F0C0000 call FAST_APL.00407116
00406487 61 popad
00406488 9D popfd
00406489 50 push eax
0040648A 68 00104000 push FAST_APL.00401000
0040648F C2 0400 retn 4
En primer lugar esta rutina carga
en el registro edi la RVA y la longitud la sección que antes
de ser empaquetada fue semiencriptada, modificando los argumentos de los opcodes call
y jmp. Debido a que toma el valor de la RVA, debe añadirla
la ImageBase. La longitud del código lo almacena en el registro ecx,
que usará como contador. A partir de este momento se entra en un bucle que sólo sale cuando ecx es menor o igual a 0. Dentro del bucle hay que observar que edi
es usado como puntero que apunta al código que se tiene que examinar, esi
se usa como un offset para resituar más rápidamente el puntero. Los registros ebx
y edx se usan para cálculos de posiciones relativas, y
con ellos se van a ir modificando los argumentos de los opcodes call y
jmp. Concretamente el registro ebx
lleva la posición relativa que se está leyendo. El registro eax
se usa para cargar ahí el código que se examina, word a word.
En 406372 se carga en eax
secuencialmente cada uno de los word. Y a partir de este momento se chequea si ese word contiene alguno
de los opcodes que nos interesa modificar.
De 406375 a 406379 se mira si el
opcode es E8h o E9h, es decir call o jmp
long. Si es uno de estos dos se salta a 4063B3, donde invierte el orden del argumento (dirección),
y le resta la posición relativa actual.
En 40637B comprueba si el opcode
es 2517h+E8h= 25FFh (= jmp dword ptr[NN]). Lo que hace en este caso
es saltar a 4063D2 donde le suma al argumento (NN) el valor del registro ebx, este registro se inicializa a 0, y cada vez que es usado se le resta 4. Por tanto
la primera vez que ocurre encuentra este opcode su argumento permanece inalterado, pero la siguiente vez se le
resta 4, la siguiente 8, la siguiente 0Ch, etc... Este opcode aparece casi de modo exclusivo para indexar los valores
de la IAT.
De
406381 a 40638D se comprueba si el opcode es un salto relativo, verificando para ello que el opcode sea de tipo
0F80h .. 0F8Fh, los cuales corresponden a: jo,
jno, jb, jnb,
je, jne, jbe,
ja, js, jns,
jpe, jpo, jl,
jge, jle, jg (todos
ellos de tipo long). Al ser
de dipo long, el argumento es una dirección realtiva de 32bits, igual que con call
y con jmp,
aunque en esta ocasión los argumentos no están invertidos, y por ello lo único que hace es
restarles el valor de ebx.
Una
vez rastrea todo el código lo último que le queda por hacer es construir la tabla de la IAT, tarea
que normalmente hace el loader. Sin embargo, al salir de este último bloque, en 4063E2 y 404063E3 hace un
call. Uno de los plugins
que vimos al inicio que tenía como opción el PeCompact era el pre-operative, pero también
tiene uno post-operative. Precisamente es este call el
encargado de llamar al plugin post-operative. Si no hay ningún plugin post-operative el call
salta a una zona que está rellenada con 0C3h (retn). Inmediatamente, al retornar del call
llama a en 4063F0 a VitualFree, liberando el buffer de memoria que fue
creado anteriormente.
El
siguiente call que aparece
llama a una rutina que se encuentra en 406492. Esta rutina es la encargada de rellenar la IAT. Antes de entrar
en su análisis adelantar solamente que la rutina devuelve el flag carry a 1 si hubo algún error al
cargar la IAT, y si no hay ningún error vuelve con el flag carry a 0. Si hay algún error en la construcción
de la IAT se ejecuta todo el código comprendido entre 4063FD y 406470, que sencillamente muestra un MessageBoxA
con el módulo y la función API donde se ha producido el error (normalmente se debe a que no se puede
encontrar esa función en ese módulo), llamando finalmente a ExitProcess (ver los comentarios del
código añadidos por OllyDbg para clarificar la rutina).
Si
no ha habido ningún error al cargar la IAT nuevamente se llama a una rutina de carga de pulgins, situando
previamente en esi y en edi LoadLibraryA y GetProcAddress. Finalmente,
recupera todos los registros mediante popad y
popfd. En 406489 mete en
la pila el valor de eax pasado
por el loader (normalmente es el EntryPoint), y el OEP (que ha sido modificado anteriormente), para salta finalmente
a ese OEP mediante el retn 4.
Realmente el meter eax en
la pila no sirve de nada, pues el retn 4
lo saca al saltar al OEP.
Analicemos
ahora la rutina que construye la IAT. Antes de analizar qué hace esta rutina deberíamos entender
qué es y como funciona la Import Table. Muy por encima decir que hay 2 tipos de tablas para las importaciones.
Una tabla que la Import Table Address (Tabla de direcciones de importaciones), y la Import Table como tal (Tabla
de Importaciones). En la segunda hay información sobre qué módulos necesita el fichero exe,
y qué funciones de esos módulos utiliza el fichero exe. La primera tabla (IAT) inicialmente en el
fichero está vacía, ya que es rellenada/construida por el loader del sistema. La estructura de la
Import Table es muy sencilla, ya que consta de 20 bytes por cada módulo que importa, añadiendo como
marcador de final otros 20 bytes puestos a 0.
Aunque
en winnt.h existen multitud de estructuras definidas que hacen referencia a la Import, no hay ninguna que defina
esta estructura. Los nombres y la definición lo he tomado de un documento de Johannes Plachy, por parecerme
bastante clarificador.
Typedef struct tagImportDirectory
{
DWORD dwRVAFunctionNameList;
DWORD dwUseless1;
DWORD dwUseless2;
DWORD dwRVAModuleName;
DWORD dwRVAFunctionAddressList;
}
Este
tag/estructura, se repite consecutivamente por cada uno de los módulos que el fichero exe necesite. Es esta
estructura la que marca el tamaño de la Import. Es decir, si hay 4 módulos a importar, corresponderían
20 bytes de estructura a cada módulo, 20 * 4 = 80 bytes, a esto habría que sumarle una estructura
de 20 bytes puestos a 0 (que es la que marca el final), y por tanto sería 80 + 20 = 100 bytes. Por tanto
el tamaño de Import para ese fichero sería de 100 bytes (64h).
dwRVAModuleName
es la RVA que apunta al nombre del módulo que se debe cargar (el nombre del DLL). El primer valor que
aparece en la estructura es la RVA que apunta a una lista de RVAs que a su vez apuntan a los nombres de las funciones
que tiene que importar de este módulo. En este punto hay que tener cuidado, pues mientras que dwRVAModuleName
apunta directamente al primer carácter del nombre del módulo, los RVAs de los nombres de las
funciones que hay en la lista no apuntan al primer carácter, sino a 2 caracteres antes. Finalmente, dwRVAFunctionAddressList
apunta a la zona de la IAT donde se deben poner las direcciones reales que le corresponden a cada función
(figura 7).
Pues
bien, esta tarea, que normalmente la hace el loader del sistema, es la que hace ahora la rutina que vamos a analizar.

Fig. 7. Esquema de la estructura que forma la ImportTable. Obviamente
cada módulo asigna una zona distinta dentro de la ImportAddressTable.
La
rutina que tiene que hacer todo este trabajo en el unpacker del PeCompact hemos visto que es llamada en último
lugar, y que empieza en 406492. Veamos su aspecto...
00406492 8BB5 37A64000 mov esi,dword ptr ss:[ebp+40A637]
00406498 0BF6 or esi,esi
0040649A 74 18 je short FAST_APL.004064B4
0040649C 8B95 A6A04000 mov edx,dword ptr ss:[ebp+40A0A6]
004064A2 03F2 add esi,edx
004064A4 E8 0F000000 call FAST_APL.004064B8
004064A9 72 0B jb short FAST_APL.004064B6
004064AB 83C6 14 add esi,14
004064AE 837E 0C 00 cmp dword ptr ds:[esi+C],0
004064B2 75 F0 jnz short FAST_APL.004064A4
004064B4 F8 clc
004064B5 C3 retn
004064B6 F9 stc
004064B7 C3 retn
004064B8 C785 0DA64000 000> mov dword ptr ss:[ebp+40A60D],0
004064C2 8B0E mov ecx,dword ptr ds:[esi]
004064C4 8B7E 10 mov edi,dword ptr ds:[esi+10]
004064C7 0BC9 or ecx,ecx
004064C9 75 02 jnz short FAST_APL.004064CD
004064CB 8BCF mov ecx,edi
004064CD 03CA add ecx,edx
004064CF 03FA add edi,edx
004064D1 8B46 0C mov eax,dword ptr ds:[esi+C]
004064D4 0BC0 or eax,eax
004064D6 0F84 95000000 je FAST_APL.00406571
004064DC 03C2 add eax,edx
004064DE 51 push ecx
004064DF 52 push edx
004064E0 8985 E3A44000 mov dword ptr ss:[ebp+40A4E3],eax
004064E6 50 push eax
004064E7 FF95 29A64000 call dword ptr ss:[ebp+40A629]
004064ED 5A pop edx
004064EE 59 pop ecx
004064EF 0BC0 or eax,eax
004064F1 0F84 7C000000 je FAST_APL.00406573
004064F7 8985 33A64000 mov dword ptr ss:[ebp+40A633],eax
004064FD 8B19 mov ebx,dword ptr ds:[ecx]
004064FF 83C1 04 add ecx,4
00406502 0BDB or ebx,ebx
00406504 74 6B je short FAST_APL.00406571
00406506 8BC3 mov eax,ebx
00406508 F7C3 00000080 test ebx,80000000
0040650E 74 18 je short FAST_APL.00406528
00406510 81E3 FFFF0000 and ebx,FFFF
00406516 C785 E7A44000 010> mov dword ptr ss:[ebp+40A4E7],1
00406520 899D DFA44000 mov dword ptr ss:[ebp+40A4DF],ebx
00406526 EB 14 jmp short FAST_APL.0040653C
00406528 C785 E7A44000 000> mov dword ptr ss:[ebp+40A4E7],0
00406532 03DA add ebx,edx
00406534 43 inc ebx
00406535 43 inc ebx
00406536 899D DFA44000 mov dword ptr ss:[ebp+40A4DF],ebx
0040653C 51 push ecx
0040653D 52 push edx
0040653E 80BD C3A74000 C3 cmp byte ptr ss:[ebp+40A7C3],C3
00406545 74 14 je short FAST_APL.0040655B
00406547 53 push ebx
00406548 FFB5 33A64000 push dword ptr ss:[ebp+40A633]
0040654E FFB5 19A64000 push dword ptr ss:[ebp+40A619]
00406554 E8 BD030000 call FAST_APL.00406916
00406559 EB 0D jmp short FAST_APL.00406568
0040655B 53 push ebx
0040655C FFB5 33A64000 push dword ptr ss:[ebp+40A633]
00406562 FF95 19A64000 call dword ptr ss:[ebp+40A619]
00406568 5A pop edx
00406569 59 pop ecx
0040656A 0BC0 or eax,eax
0040656C 74 05 je short FAST_APL.00406573
0040656E AB stos dword ptr es:[edi]
0040656F EB 8C jmp short FAST_APL.004064FD
00406571 F8 clc
00406572 C3 retn
00406573 F9 stc
00406574 C3 retn
Aunque
parece una rutina larga, se trata de una pequeña rutina que un par de bucles, que se encargan de ir cargando
los módulos en memoria con LoadLibraryA, y posterior ir rastreando la lista de funciones y cargándolas
en la IAT mediante GetProcAddess. Bueno, veamos por partes cómo lo hace.
En primer lugar lo que hace es usar esi como un puntero apuntando a la tabla de importaciones.
El valor RVA de la Import Table lo toma en 406492, y es un valor que nos va a ser tremendamente útil a la
hora de reconstruir el fichero que obtengamos al volcar la memoria.
Una vez toma la dirección de la Import Table, inicia un bucle pequeño
que comprende de 4064A4 a 4064B7. En este bucle lo que hace es ir cogiendo del inicio de la Import Table los tags/estructuras,
terminando el bucle cuando alguna de ellas tenga dwRVAModuleName (esi+0C) a 0. El el bucle se llama a la subrutina 4064B8, que ahora veremos qué
hace. Solo saber que esa subrutina devuelve el flag carry puesto a 1 si ha habido un error.
La
subrutina 4064B8 es la que se tiene que encargar de leer dwRVAModuleName, dwRVAFunctionNameList e
ir cargando las funciones en dwRVAFunctionAddressList .Veamos cómo lo hace.
En 4064C2 y 4064CB hace que ecx sea dwRVAFunctionNameList, y que edi
sea igual a dwRVAFunctionAddressList. Si por cualquier causa dwRVAFunctionNameList es 0, hace
que ecx sea igual a dwRVAFunctionAddressList. A continuación
a ambos valores les suma la ImageBase, para calcular su dirección real.
Lo siguiente es cargar el dwRVAModuleName
en el registro eax. Si por cualquier causa extraña este valor
fuera 0, salta a 406571 poniendo el flag carry a 0, es decir, no hay error (este chequeo no tiene mucho sentido,
pues este chequeo se hace en el bucle principal que lee las estructuras). A este RVA también le suma la
ImageBase que está en edx, para obtener la dirección real.
Debido a que el unpacker si hay
un error debe mostrar información, debe guardar qué módulo se está tratando en cada
momento. Eso lo hace guardando ciertos valores en una zona de memoria. En 4064F7, por ejemplo, guarda el registro
eax (que en ese momento está apuntando al nombre del módulo), de tal modo que si después se
produce un error, se tomará información de ese valor guardado (ver código de las direcciones
406436 a 40644C anteriormente explicado). Después mediante GetModuleHandleA toma el valor de esa librería,
si existe algún problema con esta API deja eax a 0, saltando
a 406573, donde pone el flag carry a 1 (error).
Una vez hecho esto se inicia un
nuevo bucle que va rastreando los RVA que hay en dwRVAFunctionNameList+ImageBase. En el momento que encuentra
un RVA que sea 0 interpreta que la lista de RVAs a los nombres de funciones ha terminado. Con cada RVA calcula
la dirección real del nombre de la API, para obtener su dirección y ponerla en la IAT.
004064FD 8B19 mov ebx,dword ptr ds:[ecx]
004064FF 83C1 04 add ecx,4
00406502 0BDB or ebx,ebx
00406504 74 6B je short FAST_APL.00406571
Enebx
mete la RVA de la lista de RVAs que apuntan a los nombres de funciones, posiciona ecx
al próximo RVA de la lista, y si el RVA leído es 0, salta a 406571, donde pone el flag carry
a 0 (no error).
Lo siguiente que se hace con el RVA
leído de la lista chequear si el bit 31 está a 1 o a 0.
00406508 F7C3 00000080 test ebx,80000000
0040650E 74 18 je short FAST_APL.00406528
Si el bit 31 está a 0 se
interpreta que es un Import por nombre, y si el bit 31 está a 1 se entiende que el Import se hace por ordinales.
Si es por ordinales mete un 1 en[ebp+40A4E7], y si es por nombres, mete
un 0. Esta variable se usa en caso de error, para mostrar el mensaje de error (error en la función %s, o
erro en el ordinal %d). Si la importación se hace por ordinales mete el valor del ordinal (limitado a FFFFh)
en ebp+40A4DF, que es la variable usada también para imprimir
la cadena de error si lo hubiere.
Si es por nombre, salta a la dirección
406528, donde calcula la dirección real sumando al RVA la ImageBase. A continuación mediante dos
inc ebx posiciona el puntero en el primer carácter del nombre
de la función (hay que recordar que la tabla de RVA apuntando a los nombres de las funciones no apuntan
realmente al primer carácter, sino 2 bytes antes). Una vez posiciona bien el puntero lo guarda en [ebp+40A4DF] (esto es para poder mostrar el mensaje de error si se diera el
caso).
00406510 81E3 FFFF0000 and ebx,FFFF ;ordinales limitados a 0FFFFh
00406516 C785 E7A44000 010> mov dword ptr ss:[ebp+40A4E7],1 ;importaciones por ordinales
00406520 899D DFA44000 mov dword ptr ss:[ebp+40A4DF],ebx ;ordinal actual que se está tratando
00406526 EB 14 jmp short FAST_APL.0040653C
00406528 C785 E7A44000 000> mov dword ptr ss:[ebp+40A4E7],0 ;importaciones por nombre de función
00406532 03DA add ebx,edx
00406534 43 inc ebx
00406535 43 inc ebx ;posiciona el puntero en el primer char
00406536 899D DFA44000 mov dword ptr ss:[ebp+40A4DF],ebx
Antes de cargar la dirección
real de la función API con GetProcAddess, debemos fijarnos que uno de los plugins del PeCompact es el GPA,
es decir, un hook para el GetProcAddess. Eso es precisamente lo que se hace en la zona comprendida desde 40653E
hasta 406559.
0040653E 80BD C3A74000 C3 cmp byte ptr ss:[ebp+40A7C3],C3
00406545 74 14 je short FAST_APL.0040655B
00406547 53 push ebx
00406548 FFB5 33A64000 push dword ptr ss:[ebp+40A633]
0040654E FFB5 19A64000 push dword ptr ss:[ebp+40A619]
00406554 E8 BD030000 call FAST_APL.00406916
00406559 EB 0D jmp short FAST_APL.00406568
En este pequeño bloque lo
que se hace es chequear si existe el plugin instalado (mira si la primera instrucción de la rutina del
plugin es 0C3h (retn). Si no es retn
el primer opcode de esa rutina mete 3 datos en la pila, y salta a la rutina del plugin, que se encuentra en 406916.
Los 3 datos que mete en la pila antes de llamar al plugin son: Handle, Handle del móudlo, y ebx
(que contiene el ordinal o el puntero al nombre de la función a cargar). Al volver del plugin con el jmp 406568 salta el siguiente bloque, que es la rutina normal de GetProcAddess.
La rutina normal de GetProcAddess
es la siguiente:
0040655B 53 push ebx
0040655C FFB5 33A64000 push dword ptr ss:[ebp+40A633]
00406562 FF95 19A64000 call dword ptr ss:[ebp+40A619]
Consiste tan solo en dospush,
que meten en la pila los argumentos para llamar después a la API GetProcAddess. Los argumentos que mete
en la pila son el handle del módulo, y el puntero al nombre de la función (u ordinal de la función).
Finalmente la rutina chequea el valor
devuelto por el plugin o por GetProcAddess en eax. Si eax
ha vuelto con un valor igual a 0 significa que se ha producido un error al cargar esa función, saliendo
de todo el bucle y poniendo el flag de carry a 1 (stc). Si no ha habido
error eax contiene la dirección de la API, la
cual mediante stos dword ptr es:[edi] es guardada en
la posición que le corresponde de la IAT.
Y
esto sería lo que hace todo el bucle que reconstruye
la IAT.
|
| CONCLUSIONES |
|
Bien, quizás esta sea la
parte que muchos pensabais que iba a hacer al principio. Explicar rápidamente cómo se hace un dump
de un fichero comprimido con este packer, y como reconstruirlo para que sea operativo.
Para reconstruirlo lo ideal sería
poder hacer un volcado una vez haya desempaquetado toda la sección con la Tabla de Importaciones, pero antes
de que genere los datos con la IAT. Sin embargo sí que deberíamos tener la información de
dónde ha desempacado la Tabla de Importaciones.
La idea es bien sencilla. Si nos fijamos
bien, todas las secciones se encuentran desempaquetadas al llegar al call que
genera la IAT. En mi ejemplo ese call está en 4063F6. Se trata
de un call que es fácilmente localizable, pues justo después
tiene un salto condicional si no hay carry (jnc/jnb). El salto va inmediatamente
a la rutina que llama al plugin post-operative, y al salto que nos lleva al OEP.
La idea para el dump sería
detener el packer justo en ese call a la rutina que genera la IAT, y
no ejecutar la llamada a esa rutina (podemos nopear el call).
Lo que sí debemos ejecutar antes de hacer el volcado es el call a
la rutina del plugin post-operative. Por tanto deberíamos hacer el dump del proceso cuando estemos situados
sobre el popad. Antes de hacer el volcado debemos mirar el dword que
hay en la dirección ebp+40A637. De esa dirección es donde
lee la rutina que genera la IAT la RVA de la Tabla de Importaciones. Es decir, de esa dirección obtenemos
la RVA de la Tabla de Importaciones. Para calcular su longitud es sencillo. Y podemos hacerlo antes de dumpear
el proceso.
Bien, pues apuntamos esa RVA, y sobre
el popad podemos parchear el famoso jmp
eip. Los que uséis el OllyDbg tenéis la ventaja que podéis volcar sin necesidad de
parchear ;o). Y una vez volcado tendremos que editar la cabecera PE. En la parte de Data Directory de la cabecera
PE debéis editar la variable Import, poniendo ahí la RVA que habéis obtenido leyendo el
dword de ebp+40A637.
Para
calcular la longitud de la Import es sencillo. Debeis
mirar los datos que corresponden a la Import. Una vez
vistos, hay que ir mirándolos de 20 en 20 bytes.
Y cuando encontréis un bloque de 20 bytes que sean
todos 0, ese es el final del Import. La longitud también
debe contar esos 20 bytes a 0. Por tanto la longitud mínima
de una Import es de 20 bytes (todos a 0). Para calcular
la longitud de la Import podéis volver a leer la
parte de este tutorial donde he explicado la estructura
de la Tabla de Importaciones.
|
| PARA LOS ERUDITOS: EL ALGORITMO DE DESCOMPRESIÓN aPLiB |
|
Cuando empecé a mirar los
algoritmos que usaba el PeCompact en la compresión observé que había una pega principalmente:
Jeremy Collake (el autor del packer) había usado 2 algoritmos distintos: el suyo propio (JCALG1), y otro
algoritmo de Joergen Ibsen (aPLiB). El JCALG1 no es ningún problema, pues es un algoritmo abierto, del cual
J. Collake ha publicado fuentes, pero la pega principal estaba en el aPLiB, pues J. Ibsen ha publicado una librería
que es pública, para comprimir y descomprimir con su algoritmo, pero no hay fuentes (por tanto no es un
algoritmo abierto). Así pues me puse manos a la obra, para desentrañar los misterios del algoritmo
aPLiB.
Primero deberíamos entender
qué es lo que hace un empaquetador de datos. Cosa, que imagino todos sabemos, es que todos los algoritmos
de compresión intentar quitar los datos que se van repitiendo, sustituyéndolos por un código
de control que indica que es un dato repetido que ya se ha almacenado en otro lugar (ese dato de control debe ocupar
menos que el propio dato). Esto, que en teoría es muy bonito, en la práctica es una lucha constante
por encontrar un algoritmo que ocupe poco, que consuma pocos recursos en memoria, que no tenga procesos muy reiterativos,
y encima que tenga un buen ratio de compresión.
El modo en que esto se hace en el aPLiB
es sencilla. Podemos decir que hay unos datos que los consideraremos como datos propiamente, y otros que son datos
de control. El packer lo que hace es ir intercalando esos datos de control entre los datos propiamente... Ahora
veremos como funciona el algoritmo de descompresión, y lo entenderemos mucho mejor.
He de advertir que prácticamente
todo el código ASM del algoritmo consiste en comprobaciones de flags, y de rotaciones. A decir verdad cuando
vi el código desensamblado fui yo el primer sorprendido... solo me vino un pensamiento: ¡¡¿¿esto
es la rutina??!!
Bueno, pues veamos su aspecto:
004090E2 C8 000000 enter 0,0
004090E6 55 push ebp
004090E7 8B75 08 mov esi,dword ptr ss:[ebp+8]
004090EA 8B7D 0C mov edi,dword ptr ss:[ebp+C]
004090ED FC cld
004090EE B2 80 mov dl,80
Estas
primeras líneas lo que hacen es inicializar los valores. En esi
sitúa la dirección que contiene los datos empaquetados,
y en edi la
dirección donde se tienen que desempaquetar. Después limpia el flag de dirección, y mete 80h
en dl (este
dato es lo que va a usar como contador de 8 bits - 80h = 10000000b)
004090F0 8A06 mov al,byte ptr ds:[esi]
004090F2 46 inc esi
004090F3 8807 mov byte ptr ds:[edi],al
004090F5 47 inc edi
004090F6 02D2 add dl,dl
004090F8 75 05 jnz short FAST_APL.004090FF
El
primer dato es copia desde esi a
edi literalmente,
es decir, el primer byte es interpretado como dato literal que se tiene que copiar. Después se actualiza
el puntero edi para
seguir descomprimiendo. La suma del registro dl consigo mismo es como si rotásemos ese registro de 8 bits a la izquierda.
Hay que tener en cuenta que esta primera vez al sumar 10000000b con 10000000b se produce un resultado de 00000000b,
poniendo el flag carry a 1.
004090FA 8A16 mov dl,byte ptr ds:[esi]
004090FC 46 inc esi
004090FD 12D2 adc dl,dl
004090FF 73 EF jnb short FAST_APL.004090F0
Si
al rotarse el registro dl se
observa que su valor pasa a ser 0, se entiende que se ha leído un código completo de control. Los
códigos de control son bytes, que después son interpretados bit a bit.
Bien,
analicemos esta operación. Inicialmente el registro dl vale 80h, pero al hacer una suma sobre sí mismo provoca que el carry
pase a valer 1 (es lo que va a usar como marca de que ha leído 8 bits) y que el registro en sí pase
a valer 0. En esta situación lo que hace el algoritmo es leer un byte del código empaquetado, interpretándolo
como un código de control. A ese código de control le rota a la izquierda (con adc), de tal modo que el bit
7 de dl
para a ser el carry actual, y el carry anterior es puesto en el bit 0. Ese carry anterior metido en el bit 0 es
lo que se usará como marca para saber que se han leído los 8 bits que contiene el código de
control cargado en dl.
En
este primer bloque, desde 4090F0 hasta 4090FF lo que se hace es leer un bit del código de control (de izquierda
a derecha). Si ese bit es 0, interpreta que debe ser leído un byte como dato, y añadido a la cadena
desempaquetada (si el bit es 0 se produce el salto de 4090FF).
Por
tanto, si tenemos 3 bytes que deben ser leídos y copiados de este modo, tenemos que realmente no ocuparían
24 bits (8 bits cada uno), sino que además hay que añadir un bit 0 a cada de uno, que es el que
indica que deben ser copiados de este modo... es decir, que 24 bits serían interpretados con 27 bits. Este
sería el caso más nefasto, es decir, que todos los bytes sean diferentes, y deban ser leídos
como argumentos.
El
peor de los casos sería una secuencia a comprimir de 255 bytes (2040 bits), cuyos valores fueran (1,2,3,4...255).
En ese caso cada byte se debería guardar como argumento literal, lo que implicaría que a cada byte
se le añadiera el código de control 0... dicha secuencia al comprimirla ocuparía los 2040bits,
más 255 bits más de códigos de control. El byte 0 no lo he añadido a posta, ya que
se codifica siempre con 7 bits.
Hemos
de tener en cuenta que la lectura de cada bit del código de control se hace pasando ese bit por el flag
carry. Y por cada lectura de un bit hay que leer si es el último y está a 1 (la marca que hemos metido
con 80h para marcar el final del código de control), ya que en este caso hay que leer un nuevo código
de control.
Cada
vez que veamos un bloque similar a este...
00409101 02D2 add dl,dl
00409103 75 05 jnz short FAST_APL.0040910A
00409105 8A16 mov dl,byte ptr ds:[esi]
00409107 46 inc esi
00409108 12D2 adc dl,dl
...podemos
traducirlo como que se ha leído un nuevo bit del código de control, y se chequea por si es el último.
0040910A 73 4A jnb short FAST_APL.00409156
Hasta este punto se ha leído
un nuevo bit (el previo leído es 1), y ahora la comparación hace que si el segundo bit leído
es 0 se salte a 409156... si el segundo bit leído es 1 se continúa la ejecución del programa.
0040910C 33C0 xor eax,eax
0040910E 02D2 add dl,dl
00409110 75 05 jnz short FAST_APL.00409117
00409112 8A16 mov dl,byte ptr ds:[esi]
00409114 46 inc esi
00409115 12D2 adc dl,dl
00409117 0F83 E1000000 jnb FAST_APL.004091FE
Aquí
se mira el valor del tercer bit leído. Si es 0 (leído en total 110 se salta a 4091FE), y si es
1 (leído 111) se continúa la ejecución.
0040911D 02D2 add dl,dl
0040911F 75 05 jnz short FAST_APL.00409126
00409121 8A16 mov dl,byte ptr ds:[esi]
00409123 46 inc esi
00409124 12D2 adc dl,dl
00409126 13C0 adc eax,eax ;primer bit del argumento
00409128 02D2 add dl,dl
A
continuación se va a ejecutar este trozo de código 4 veces, para leer 4 bits consecutivos, y metiéndolos
en eax.
De este modo podemos decir que se ha leído 111 del código de control, y 4 bits más como
argumento que se guarda en eax.
0040912A 75 05 jnz short FAST_APL.00409131
0040912C 8A16 mov dl,byte ptr ds:[esi]
0040912E 46 inc esi
0040912F 12D2 adc dl,dl
00409131 13C0 adc eax,eax ;segundo bit del argumento
00409133 02D2 add dl,dl
00409135 75 05 jnz short FAST_APL.0040913C
00409137 8A16 mov dl,byte ptr ds:[esi]
00409139 46 inc esi
0040913A 12D2 adc dl,dl
0040913C 13C0 adc eax,eax ;tercer bit del argumento
0040913E 02D2 add dl,dl
00409140 75 05 jnz short FAST_APL.00409147
00409142 8A16 mov dl,byte ptr ds:[esi]
00409144 46 inc esi
00409145 12D2 adc dl,dl
00409147 13C0 adc eax,eax ;cuarto bit del argumento
00409149 74 06 je short FAST_APL.00409151
Finalmente
en el último bit leído y guardado en eax, se comprueba si el argumento es 0. Si el argumento es 0 se entiende que
se debe añadir un byte 0 en la cadena desempaquetada (por tanto el byte 0 se codificaría de este
modo: 111, 0000; es decir, ocupa 7 bits). Si el argumento es distinto de 0 es interpretado como un offset relativo
y negativo desde el cual hay que tomar el dato de la cadena ya desempaquetada. Por ejemplo, si el código
de control es 111, y el argumento es 0110, se entiende que que el dato que hay que añadir a la cadena
desempaquetada es el mismo que hay en la cadena ya desempaquetada en la posición actual menos 0110b (=6h).
0040914B 57 push edi
0040914C 2BF8 sub edi,eax ;calcula la posicion actual-argumento
0040914E 8A07 mov al,byte ptr ds:[edi] ;lee el dato que hay ahí
00409150 5F pop edi
00409151 8807 mov byte ptr ds:[edi],al ;añade el dato a la cadena desemp.
00409153 47 inc edi
00409154 EB A0 jmp short FAST_APL.004090F6 ;lee un nuevo bit de control
Si
lo que se lee es el código de control 110 salta a 4091FE. Donde hace las siguientes operaciones:
004091FE 8A06 mov al,byte ptr ds:[esi]
00409200 46 inc esi
00409201 33C9 xor ecx,ecx
00409203 C0E8 01 shr al,1
00409206 74 12 je short FAST_APL.0040921A
Se
lee en al un byte de las secuencia de datos comprimidos. Y mediante shr se saca el bit0 del registro al pasándolo al flag carry. Por tanto al pasa a ser un valor significativo
de 7 bits. Si ese valor de al es 0, se interpreta que es el final de los datos empaquetados, saltando al final
de la subrutina, que se encuentra en 40921A. Por tanto, la secuencia que indica que se ha llegado al final de los
datos empaquetados sería 110, situando en el siguiente byte un valor que será 0 ó 1 (posibles
valores del valor binario 0000000x)
00409208 83D1 02 adc ecx,2
0040920B 8BE8 mov ebp,eax
0040920D 56 push esi
0040920E 8BF7 mov esi,edi
00409210 2BF0 sub esi,eax
00409212 F3:A4 rep movs byte ptr es:[edi],byte ptr ds:[edi]
00409214 5E pop esi
00409215 E9 DCFEFFFF jmp FAST_APL.004090F6
Este
ultimo bloque de código es sencillo. Mediante adc ecx,2
pone a ecx
con un valor de 2+carry. Si seguimos examinando un poco veremos
que al se usa como offset relativo para tomar el valor que hay que añadir a los datos desempaquetados, los
cuales son copiados de esi a
edi mediante
un rep. Por tanto ecx es
el counter del número de bytes que hay que copiar. Luego ya podemos interpretar la secuencia de control.
La cual tendría esta forma 110+byte_siguiente. Siendo el byte siguiente de este modo dddddddc. Los bits
marcados con d indican el desplazamiento hacia atrás de la posición actual del desempaquetado de
donde hay que coger los datos. Y el bit c indica el valor que hay que añadir a ecx (inicializado por defecto a 2). Por tanto, si c es 0 ecx vale 2, y si c es 1 ecx vale 3. Hay que
tener en cuenta una cosa. Que el valor relativo que toma del argumento (el valor de 7 bits) queda también
guardado en el registro ebp,
este dato es importante. Pues el rango que guarda es porque da supuesta la posibilidad de que los datos dentro
de ese rango se repitan nuevamente. Este valor de ebp se usa en otros códigos de control que ahora veremos. Fijémonos
que este código de control con su argumento de 8 bits son en total 11 bits. En el peor de los casos es para
copiar 2 bytes (16 bits), y en el mejor de los casos es para copiar 3 bytes (24 bits).
Resumiendo,
¿qué ocurre si el desempaquetador se encuentra el código de control 110? Lee el siguiente
byte, y eso es lo que toma como argumento. De ese argumento saca 1 bit que le indica si tiene que copiar 2 ó
3 bytes. Y de los 7 bits restantes del argumento saca el valor del desplazamiento relativo de donde tiene que copiar
esos 2 ó 3 bytes.
Ahora
veamos qué ocurre si el código de control no es 111, ni 0, ni 110, sino 10...
00409156 B8 01000000 mov eax,1 ;inicializa eax con 1
0040915B 02D2 add dl,dl
0040915D 75 05 jnz short FAST_APL.00409164 ;lee un 1 bit más
0040915F 8A16 mov dl,byte ptr ds:[esi]
00409161 46 inc esi
00409162 12D2 adc dl,dl
00409164 13C0 adc eax,eax ;el cual es añadido a eax
00409166 02D2 add dl,dl ;lee otro bit
00409168 75 05 jnz short FAST_APL.0040916F
0040916A 8A16 mov dl,byte ptr ds:[esi]
0040916C 46 inc esi
0040916D 12D2 adc dl,dl
0040916F 72 EA jb short FAST_APL.0040915B ;si ese bit es 1 vuelve a 40915B
Bien,
ahora viene una parte un poco complicada, pues hasta ahora hemos visto códigos de control de longitud fija,
pero ahora entramos en códigos de control de longitud variable. Lo que hace en este punto el desempaquetador
es, después de haber leído del código de control 10, lee el siguiente bit, y lo añade
a eax.
Lee un bit más, el cual indica si debe continuar bits para eax, o si ya ha acabado. Si el bit que lee es 1, significa que aun quedan más
bits por leer para eax,
si el bit que lee es 0, indica que ya ha acabado.
Por
tanto la forma de este código de control sería así: 10w1x1y...z0 De tal modo que cuando
acaba la lectura de los argumentos, eax terminaría con la forma: 1wxyz (siendo w,x,y, y z valores binarios). Por
ejemplo, si se lee del código de control 10011100, eax valdría 1010 (se toman los valores subrayados, acabando
de tomar valores cuando acaba con 0.).
00409171 83E8 02 sub eax,2
00409174 75 28 jnz short FAST_APL.0040919E
Lo
siguiente que se hace es mirar qué valor tiene eax. Para ellos a eax se le resta 2. Fijémonos que la longitud mínima del código
de control anterior sería 10x0. Ya que el bit x lo lee siempre para añadirlo a eax, y es después de leer
ese bit cuando comprueba si el siguiente bit es el final (bit puesto a 0). Por tanto, si al llegar a este punto
eax vale
2, es porque el código de control anterior ha sido necesariamente 1000.
00409176 B9 01000000 mov ecx,1 ;inicializa ecx con 1
0040917B 02D2 add dl,dl ;lee un bit
0040917D 75 05 jnz short FAST_APL.00409184
0040917F 8A16 mov dl,byte ptr ds:[esi]
00409181 46 inc esi
00409182 12D2 adc dl,dl
00409184 13C9 adc ecx,ecx ;lo mete en ecx
00409186 02D2 add dl,dl ;lee un bit
00409188 75 05 jnz short FAST_APL.0040918F
0040918A 8A16 mov dl,byte ptr ds:[esi]
0040918C 46 inc esi
0040918D 12D2 adc dl,dl
0040918F 72 EA jb short FAST_APL.0040917B ;si es 1 sigue leyendo para ecx
Este
bloque es similar a lo que hemos visto antes para leer en eax, salvo que aquí los bits son leídos para ecx. Se van leyendo bits, y después
se lee el siguiente. Si el siguiente está a 1, significa que hay que leer un bit más para ecx, y si está
a 0 significa que ya se han leído todos los bits para ecx.
Por
tanto la forma quedaría de este modo: x1y1...z0, pasando ecx a tener el valor 1xyz.
00409191 56 push esi
00409192 8BF7 mov esi,edi
00409194 2BF5 sub esi,ebp
00409196 F3:A4 rep movs byte ptr es:[edi],byte ptr ds:[esi]
00409198 5E pop esi
00409199 E9 58FFFFFF jmp FAST_APL.004090F6
Este
bloque final ya nos suena mucho... lo que hace es tomar el valor relativo del offset del registro ebp (este registro queda
establecido por el código de control 110), y usa ecx como contador del numero de bits que hay que copiar. Fijémonos que
ahora como el valor ebp
ya está establecido podemos pedir que copie 3 bytes gastando menos bits... 1000 sería el código
de control mínimo. Después deberíamos indicarle cuántos bytes tiene que copiar. El
mínimo son 2 (para que ecx
valga 2 [10 en binario] deberíamos pasar como argumento 00), y el máximo podría ser lo que
nosotros consideremos.... como valor máximo ecx podría tener un valor de 32 bits. Si nos fijamos por cada bit que
metamos en ecx
debemos añadir uno más de control (o 1 para indicarle que siga leyendo, o 0 para indicarle que ya
ha leído todos). Es decir, que como ebp ya está establecido podemos reducir 2 bytes (16 bits) a 6 bits.
Es decir, en lugar de repetir el comando 110 con el argumento de 8 bits, podríamos colocar este código
de control, ya que el argumento de 8 bits de 110 quedó preservado en ecx, y en este caso solo tendríamos que indicarle el numero de bytes
a copiar. En el peor de los casos sería representar ecx
= 2, que nos ocuparía 2 bits... [en 6 bits representaríamos
16 bits] en el mejor de los casos sería representar que ecx
= FFFFFFFFh, que nos ocuparía 64 bits [en 68 bits representaríamos
34.359.738.360 bits]).
La
otra opción para este código de control es bien distinta. A este punto (40919E) se llega si eax no es 2 (y con el
valor restado ya). El valor mínimo sería si el código de control fue 1010, en cuyo caso
a este punto eax
llegaría con un valor igual a 1.
0040919E 48 dec eax
0040919F C1E0 08 shl eax,8
En
este punto el valor que hemos leído del código de control como argumento que se pasa al registro
a eax es
rotado a la izquierda 8 bits. Hemos de tener en cuenta que a ese valor de eax se le ha restado ya 3, aunque realmente solo es significativo que se le
ha restado 1, ya que eax
es inicializado con 1, lo cual significa que ese bit se da ya por supuesto a 1..
004091A2 8A06 mov al,byte ptr ds:[esi]
004091A4 46 inc esi
El
valor de al
es leído directamente como un argumento literal de 8 bits, con lo cual, mediante el argumento previo de
eax
004091A5 02D2 add dl,dl ;lee un bit
004091A7 75 05 jnz short FAST_APL.004091AE
004091A9 8A16 mov dl,byte ptr ds:[esi]
004091AB 46 inc esi
004091AC 12D2 adc dl,dl
004091AE 13C0 adc eax,eax ;lo mete de argumento en eax
004091B0 8BE8 mov ebp,eax ;el valor lo guarda en ebp
Lo
que se hace hasta aquí es sencillo. El valor que quiere recuperar como desplazamiento es un valor de 16
bits. Para ellos los 7 primeros los saca del argumento inmediato a 10. Los 8 siguientes los lee como argumento
literal, y el último bit lo lee también como argumento inmediato. Es un sistema un poco extraño,
pero la verdad es que sí que es resultón, pues con este método el byte más significativo
del número de 16 bits puede ser representado con apenas un solo bit (en el mejor de los casos), y con 14
(en el peor). Es decir, un número de 16 bits con este método queda representado con tan solo 10 bits
en el mejor de los casos... pero con 23 bits en el peor...
004091B2 B9 01000000 mov ecx,1
004091B7 02D2 add dl,dl
004091B9 75 05 jnz short FAST_APL.004091C0
004091BB 8A16 mov dl,byte ptr ds:[esi]
004091BD 46 inc esi
004091BE 12D2 adc dl,dl
004091C0 13C9 adc ecx,ecx
004091C2 02D2 add dl,dl
004091C4 75 05 jnz short FAST_APL.004091CB
004091C6 8A16 mov dl,byte ptr ds:[esi]
004091C8 46 inc esi
004091C9 12D2 adc dl,dl
004091CB 72 EA jb short FAST_APL.004091B7
Este
ultimo bloque aun nos suena... pues usa el método de ir leyendo en ecx varios bits, que le van a indicar el counter de bytes que tenemos que copiar.
La rutina es como las anteriores.. lee un bit, y lee el siguiente para ver si está a 0 o a 1. Si está
a 1 sigue leyendo bits para ecx,
y si está a 0 interpreta que ya no tiene que leer más bits para ecx.
004091CD 3D 007D0000 cmp eax,7D00
004091D2 73 1A jnb short FAST_APL.004091EE
004091D4 3D 00050000 cmp eax,500
004091D9 72 0E jb short FAST_APL.004091E9
004091DB 41 inc ecx
004091DC 56 push esi
004091DD 8BF7 mov esi,edi
004091DF 2BF0 sub esi,eax
004091E1 F3:A4 rep movs byte ptr es:[edi],byte ptr ds:[esi]
004091E3 5E pop esi
004091E4 E9 0DFFFFFF jmp FAST_APL.004090F6
El
resto de la rutina es clara. Si 500h<=eax<7D00h se añade 1 al counter, y eax
es interpretado como un desplazamiento relativo, desde el que se van a copiar los ecx
bytes. Si eax es un valor mayor o igual a 7D00hh, se salta a 4091EE,
donde sencillamente se le suman 2 al numero de bytes que hay que copiar, caso que también ocurre cuando
eax es menor o igual a 7Fh.
004091E9 83F8 7F cmp eax,7F
004091EC 77 03 ja short FAST_APL.004091F1
004091EE 83C1 02 add ecx,2
004091F1 56 push esi
004091F2 8BF7 mov esi,edi
004091F4 2BF0 sub esi,eax
004091F6 F3:A4 rep movs byte ptr es:[edi],byte ptr ds:[esi]
004091F8 5E pop esi
004091F9 E9 F8FEFFFF jmp FAST_APL.004090F6
En
cualquier otro caso (si 500h>eax>7Fh)
se copian el número de bytes indicado por ecx.
Bien,
pues esto es todo... como veis es un buen galimatías de bits, en donde se ha medido milimétricamente
todo... desde la longitud de los códigos de control, hasta la longitud máxima y mínima de
un argumento variable. Si estáis pensando en hacer algún algoritmo de compresión, este es
uno que como veis es bien sencillo de implementar, e incluso os puede dar pistas para mejorarlo.... ¿te
atreves?
Toda la
información contenida en este documento es meramente
educativa. En ningún momento se ha pretendido violar
ningún derecho ni ninguna ley de protección
de datos. Los algoritmos aPLiB y JCALG1 son propiedad
intelectual de sus autores. PeCompact es un producto cuyo
copyright pertenece a Jeremy Collake.
|
|
[ Entrada | Documentos Genéricos | WkT! Web Site ]
|
|
[ Todo el ECD |
x Tipo de Protección | x
Fecha de Publicación | x Orden Alfabético
]
|
|
|
(c) Whiskey Kon Tekila [WkT!] - The Original
Spanish Reversers.
Si necesitas contactar con nosotros ,
lee esto
antes e infórmate de cómo puedes
ayudarnos
|
|
|
|
|
|
